
Previous article

Process Mining: The Missing Link between Data Science and Process Science

We live in a hyper-connected world; a society where access to information and data is easier than ever before in history. Terms like “Big Data “ and “Data Science” have entered the common language so quickly that few people understand the profound changes they imply. Changes that affect the daily lives of all of us, and obviously drive companies to evolve.
Those that do not evolve fast enough are inevitably doomed to disappear.
Consulting companies like neosight have the mission to understand and grasp these evolutions, to help our customers appropriate them and transform: transform their information systems, transform their processes, transform their organization. So, in this blog post I’d like to share some thoughts on a couple of those key topics.
Big Data, a reality that goes beyond fiction
Big Data refers to data sets that have become so large that they exceed intuition and human analytical capabilities, even those of traditional database or information management computer tools.
Big Data is the direct consequence of an explosion of information generated through the Internet of People (social networks) and the Internet of Things, which leads to a drastic change of scale. To give you an idea: the volume of digital data created worldwide was estimated to 1.2 zetabytes per year in 2010. According to the IDC (Digital Universe Study of 2014), it will be 44 zetabytes (a zetabyte is 1021 or 1,000,000,000,000,000,000,000,000,000,000,000 bytes) in 2020.
In other words, more data has been created in the last 2 years alone than since the beginning of humanity! In 2020, 1.7 Mb of data will be created every second and for every human being.
Big Data in Enterprise
Of course, with the exception of a few giants who are shaping today's Web and make their business with the proliferation of data (Facebook: more than 500 terabytes of new data every day; YouTube: 400 hours of videos posted online every minute etc.), Big Data in most companies has a more modest dimension.
However, the explosion in the volume of data to be managed is also tangible: until the mid-2000s, few SAP R/3 systems reached or exceeded 1 Tb. Today with SAP ERP it is a commonplace volume (a "basic" installation already represents nearly 250 Gb with 100 to 150 Gb reserved space for customer data). Some systems exceed 50 Tb.
A 2016 IDG Data & Analytics survey shows that an SME/SMI manages on average 47.8 Tb of data, while for large companies it is 347.6 Tb (7 times more). Less than 19% of the companies surveyed manage a data volume of less than 1 terabyte, while for 7% it is more than 1 petabyte). For most of these companies, this volume has now increased from 60 to 150%.
Data Science is the present!
In such a context, it is natural that Data Science, a very young discipline (25 years old) has become a must. It has been booming since 2012. Data Science allows a company to explore and analyze raw data to transform it into valuable information to solve business problems.
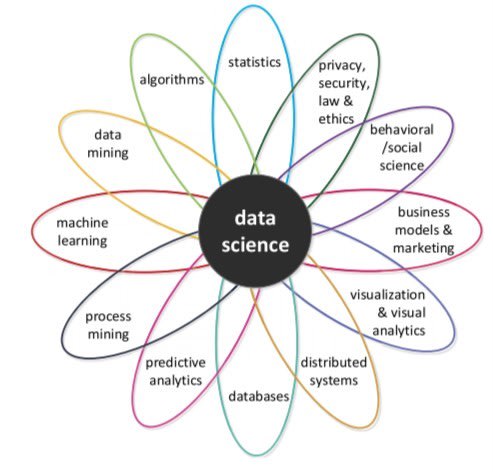
Data Science was not born from Big Data, but it makes it even more important. Its objective can be translated in a very simple way: it is about giving value to data!
To do this, Data Science borrows from different fields:
Mathematics: models, statistics
Technology: especially information- processing technology (algorithms, machine learning, etc.)
Business: data analysis must result in useful conclusions for the company, in order to improve its functioning and help it to generate more profits.
It is therefore not easy to find Data Scientists with across such a wide range of fields.
But above all, the Data Scientist must not lose sight of the ultimate goal: giving the company the means to create value.
“Process Science” is the future!
This is why other approaches are developing that are more applicable to this objective. Especially the one we can call Process Science.
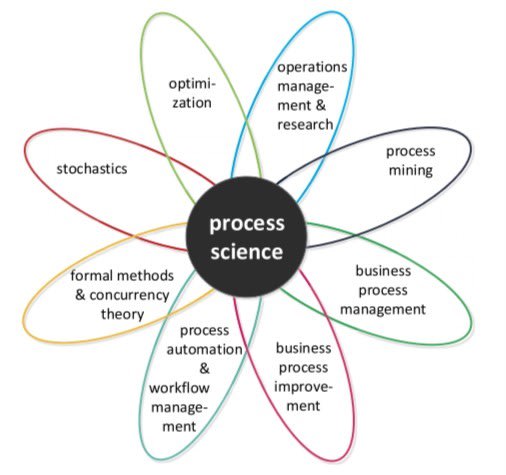
Like Data Science, it leverages information technology and mathematical processing, but also process management and operations management methods.
While Data Science is often and voluntarily used in an ''agnostic'' way, Process Science is oriented toward and relies heavily on end-to-end process modeling. It uses the data to analyze the processes in detail.
Process Science thus makes it possible to perfectly understand the progress of the company's processes, to analyze possible malfunctions or non-conformities. Even better, it makes it possible to provide answers to eliminate them, such as Business Process Management (BPM) or Business Process Improvement (BPI).
Process Mining: the missing link
There is a discipline that creates a real bridge between Data Science and Process Science: Process Mining. Its principle consists in discovering the company's processes thanks to the traces left by their execution in the information system. Process Mining makes it possible to compare the actual execution of processes with pre-established or automatically recreated models.
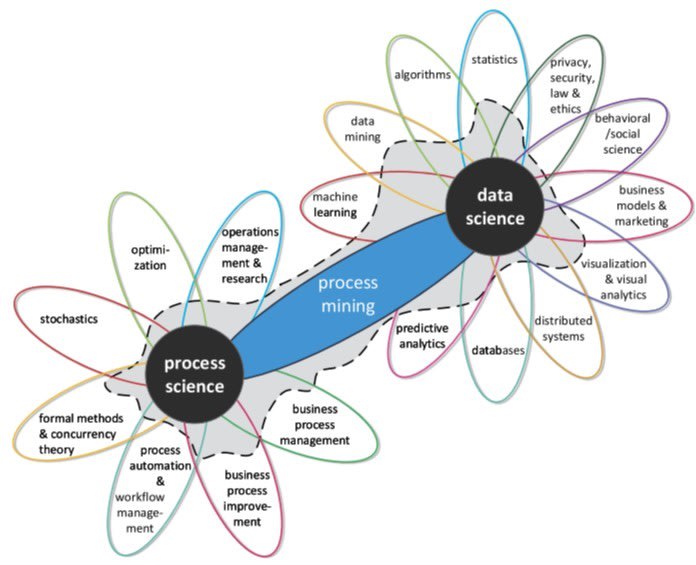
At neosight, as experts in enterprise information systems (SAP in particular), we are acutely aware of the considerable and largely under-exploited mass of information that lies dormant there.
That is why we are strong promoters of Process Mining, which allows us to reveal to our customers the value of their own data and above all to use this data for managing and facilitating the transformations they must carry out in order to remain competitive in their markets.

More blog posts on Process in Practice
